Incredible Cake Kids
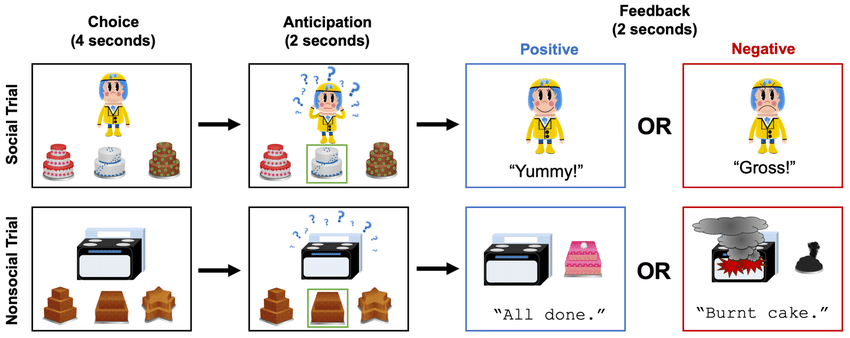
We are building an app that streamlines an existing research process, known as Incredible Cake Kids, which creates an interactive user experience for children, while also allowing us to collect valuable data that can give insight into the child's risk of mental heath deterioration. Below is a step by step process on how it works.
Steps for Cake Task
1. Show user 3 different cakes and wait for their selection
2. If they make a selection:
- 2 second delay
- Show a response (positive or negative)
- Use our model to classify their reaction to the response
- Have a 2 second delay (trial rest)
- Self-rating selection (emojis)
3. If they make a selection:
- 2 second delay
- Show a response (positive or negative)
- Use our model to classify their reaction to the response
- Have a 2 second delay (trial rest)
- Self-rating selection (emojis)
4. If they don't make a selection within 7 seconds, re-prompt the user.
5. Incorporate a 20 second delay between each task.
6. Repeat the above 8-10 times.
Machine Learning Process
We ran many machine learning models before we finalized on one we should use for our app.
Our first baseline was heavily adapted from a user on Kaggle, named Drcapa. This model was able to attend a 54% accuracy on the test set. The model uses a simple convolutional neural network with four ReLu activation layers, MaxPool layers, and a SoftMax activation layer.
Our second baseline model was using an op-for-op Pytorch re implementation of the Vision Transformer architecture from Google and loading a pre-trained model in order to develop a training pipeline for our data. The Vision Transformer involved resizing the training data images, converting to Tensor, and normalizing the image. A Pytorch data loader was used to pre process the training data and was trained on a vision transformer model with pretrained weights. The last layer was removed in order to preserve the embeddings which were then converted to Tensor in order to train a logistic regression model on the embeddings in order to classify the seven different emotion classes.
Our third baseline model was created using the MobileNetV2 in TensorFlow. We used transfer learning to adapt the image recognition model to this new task of detecting facial expressions. We created some custom layers (including convolution pooling, MaxPooling, and dropout layers) in hopes to improve the performance of the model and make it more generalizabile on unseen data. This model did not perform as well as our first baseline model, attaining a testing accuracy of 22%. As part of the process of developing this model, we did try another model which was made up of the following layers: Conv2D, MaxPooling2D, Flatten, Dropout, and Dense. This model attained 95% accuracy but only 30% validation accuracy.
Deepface is a Python framework for analyzing human faces. It's functionality includes facial recognition, expression analysis, and more. We are building our models using this pre-existing framework. The labels for the facial expressions vary slightly across our 2 datasets (FER and Dartmouth), so we first adapted for this. Then, we used Deepface's emotion recognition functionality on the Dartmouth dataset.